Doing The Thing: From Mechanical Turk to Mech Interp
For motivation/momentum purposes: Started AI Safety journey 285 days ago, documented 188 total days \(\approx\) 65% with current daily streak of "doing the thing" for 1 consecutive days!
Updates
-
Currently investigating how the QK and OV projections in the Attention Mechanism represent and process syntax,the structure of sentences, through the task of translation from "SVO" Head Inital (e.g. English) to "SOV" Head Final (e.g. Japanese) languages [daily research journal, advised by Professor Khalil Iskarous and Professor Robin Jia]
-
Previously working on extending and reproducing Anthropic's MOLTs (sparse Mixtures of Linear Transforms) as part of Georg Lange's SPAR stream on Automating Circuit Interpretability with Agents (writeup, github)
-
Reproducing Transluce's Predictive Concept Decoders (PCD) to "read the mind" of an AI model through decoding activations of a Subject Model into natural language via a Sparse Encoder and LLM Decoder Model [github]
- Started Karpathy-inspired video tutorials PCD reproduction line-by-line to make AutoInterp research more accessible [video walkthrough]
-
Playing with Fire: Proposal for a Sharing AI Safety Research with At-Risk Youth through Games [video, documentation]
- 3-step pipeline to making AIS research accessible to broader community (e.g. at-risk teenagers using AI for mental health counseling); “AIS researchers are only one piece of the puzzle” ethos
-
Reflections from first 3 weeks of 2026 abroad at LISA and attending Oxford AI Safety Initiative's ARBOx including work in progress Theory of Change
TLDR of Things I've Done Since Starting My AI Safety Journey 285 Days Ago
Projects
-
Cross-Linguistic Alignment: Does LoRA Fine Tuning a model on a task (e.g. respond in all CAPS) translate cross-linguistically? (Summary && Github)
-
Reproducing Neo et al. 2024 Interpreting Context Look Ups
-
Multilingual Semantics Probe: Looking for Steering Vectors for semantically ambiguous sentences in English but not Mandarin
-
Syntactic Dependencies in Transformers: Attention Patterns for Balanced Parentheses (Dyck) Language (Github)
Programs
-
ARBOx: 2 weeks of compressed ARENA curriculum; project on Cross-linguistic generalization of fine-tuning
-
Attended NeurIPS Mech Interp 2025 Workshop and found some cool takeaways!
-
Started being mentored by Sudhanshu Kasewa from 80,000 Hours
What is this?
Here it goes! I'm Kyle, a 4th year Computational Linguistics student at USC. This is the start of my AI Safety journey! I am very greatful to be jointly advised by Professor Khalil Iskarous and Professor Robin Jia at USC.
I learned about AI Safety from the Seattle Llama4 Hackathon on June 21st, 2025 where I learned of AI 2027. After finishing an awesome summer of engineering, I realized the problems which excite me the most lie at the crossroads of engineering and science (computation and linguistics).
The urgent need for understanding increasingly capable AI models coupled with a burning passion for working at the interdisciplinary intersection of NLP, linguistics, and engineering at scale has sharpened my goal: to become an AI Safety researcher in Mechanistic Interpretability.
Working Backwards
Sometimes (often) I get analysis paralysis or want to wait for the perfect {time, situation, background, preparation} to start which makes it difficult to get into pursuing my goals (and dreams). So this time around, I know my goal to become an AI Safety/Mech Interp researcher! After finding David Quarel's do the thing I decided that this site is a place where I will keep myself acountable for doing the thing.
- Doing --> Working through math problems, reading papers, writing down lists of possible intersections of linguistics and NLP
- The Thing --> Any of the above for at least 1 hour every day, with consistent (though not perfect) progress.
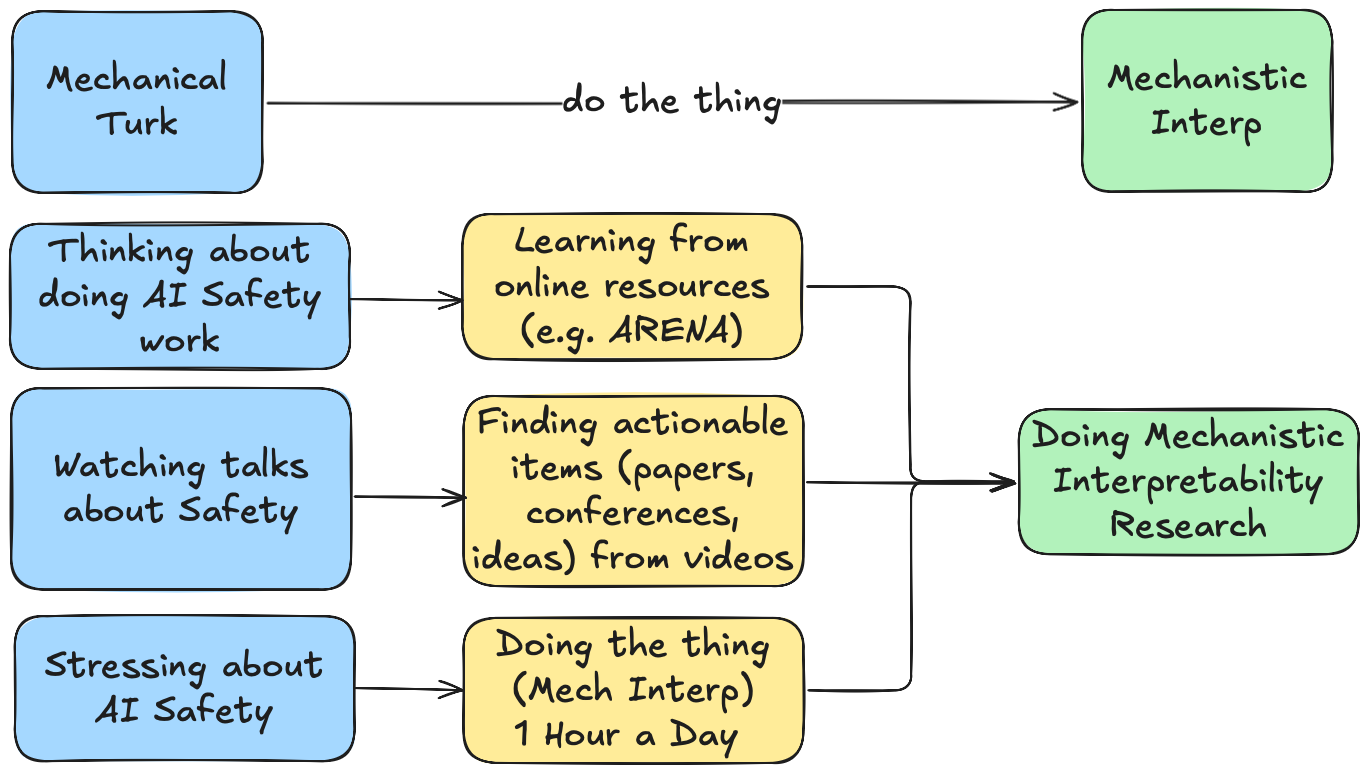
What is dlog?
I am starting this daily log or dlog where every day I will document my progress. I hope that the daily act of documenting will make me more resilient and help prove to myself how badly I want to be an interpetability researcher. With the help of AI, a macro pulls the daily logs into the summary you see below:
Extra Stuff (click me)
Wait What's Computational Linguistics?
As a Computational Linguistics student, I see Computational Linguistics as three parts:
- Linguistics = study of human language processing / cognition
- Mechanistic Interpretability = study of LLM language processing / cognition
- Computational Linguistics = Interdisciplinary approach to studying LLM language processing
The Computational Linguistics topics that pull me at 9.8 m / s^2 are concepts like Information Theory and Probabilistic Phonology in addition to Theoretical Machine Learning and NLP.
What does AI Safety and Mechanistic Interpretability mean to me?
- I hope that having deep knowledge in both the fields of linguistics and ML/NLP can help me build a more holistic understanding of LLM cognition and language processing.
- I see Mechanistic Interpretability as a sort of psycholinguistics (the study of real-time processing of language) for LLMs.
- Furthermore, I see Mechanistic Interpretability as a foundational basis for understanding AI systems. Perhaps understanding models (such as like biological organisms) can support the other branches of AI Safety (alignment, control, governance, and more).
dlog: 285 Days and Counting
Total time focused so far: 658 hrs 57 mins throughout 285 days of learning
Below are the latest updates (auto-generated).
Latest entries
-
2026-07-27 | 5 hr 0 min | Goal: Verify RASP-L Implementation Gemma3-4b-it algorithm
Cont. Try using instruction-tuned Gemma model to run translation experimentsMaxwell · Syntax
-
2026-07-21 | 4 hr 0 min | Goal: Verify RASP-L Implementation and DAS reading
Discovered that the RASP-L algorithm originally used is Seq2Seq with bidirectional attentionMaxwell · Syntax
-
2026-07-17 | 2 hr 30 min | Goal: Understand Tracr
Understanding loading ...Maxwell · Syntax
-
2026-07-16 | 9 hr 30 min | Goal: Prepare and present weekly update
Understood the RASP-L algorithm for arbitrary depth parsing!Maxwell · Syntax
-
2026-07-15 | 1 hr 0 min | Goal: Understand RASP-L constituency parsing algorithm and causal mediation
Understanding loading ...Maxwell · Syntax
-
2026-07-14 | 6 hr 30 min | Goal: Understand RASP-L constituency parsing algorithm and causal mediation
Understanding loading ...Maxwell · Syntax
-
2026-07-12 | 7 hr 0 min | Goal: Causal Intervention Experiment + RASP-L Slides
Finish scaffolding causal intervention experimentMaxwell · Syntax
-
2026-07-10 | 3 hr 50 min | Goal: Fully understand RASP-L program; thinking more about what it means to do research (Theory of Change but also life)
Started Causal Mediation code, learning new TransformerBridge API in TransformerLensMaxwell · Syntax
-
2026-07-09 | 7 hr 50 min | Goal: Weekly Update Presentation + Understand RASP-L program for constituent parsing
Continue battling RASP-L code; feels like parallel programming at the bitwise levelMaxwell · Syntax
-
2026-07-08 | 8 hr 35 min | Goal: Understand RASP-L program for constituent parsing
Understand node swapping as addition/displacement of indexesMaxwell · Syntax
Todo List
The todo list started getting too beefy and has been moved to its own todo page!